

You know that project dependency chart your PMO built last quarter? The one with a hundred-plus interconnected boxes showing how marketing depends on product, product depends on engineering, engineering depends on infrastructure, and somehow legal needs something from everyone?
Most companies treat cross-team dependency governance like air traffic control — tracking every movement, documenting every handoff, building elaborate matrices that nobody actually uses. The pattern across teams navigating dependency hell is frustratingly consistent: governance frameworks fail because they try to manage dependencies instead of preventing them from becoming blockers in the first place.
The dependency paradox that breaks most governance models
Cross-team dependencies multiply faster than teams can track them. A mid-sized product organization — say, 40 to 60 people — can easily generate a few hundred active dependencies per quarter, and that's just the official ones. That's not counting the informal ones: the "quick favor" requests, the undocumented API changes, the surprise compliance requirements that appear mid-sprint.
Traditional RACI matrices become useless at this scale. They document ownership but don't prevent bottlenecks. They clarify accountability but don't speed up decisions. And they create this false confidence that dependencies are "managed" when really they're just documented. The real operational challenge isn't knowing who's responsible. It's building a system where dependencies resolve before becoming blockers. That requires three interconnected things: lightweight ownership rules people actually follow, visual dependency boards that surface problems early, and escalation lanes that bypass organizational friction.
RACI-lite: stripping ownership models down to what actually works
Full RACI matrices — Responsible, Accountable, Consulted, Informed — create more confusion than clarity once you pass roughly 20 people. Teams spend hours debating whether someone should be "consulted" or "informed," whether you can have multiple "accountables," whether the person who's "responsible" needs sign-off from the person who's "accountable."
Stop losing track of your priorities.
Workyly helps you organize, assign, and track every task efficiently.
- Centralized task management
- Real-time collaboration
- Intelligent workflow automation
No credit card required
One team at a mid-size SaaS company spent an entire planning session arguing about RACI roles for a three-week integration project. Nothing got built. The matrix got finished, but nobody trusted it enough to actually use it when blockers appeared.
RACI-lite cuts this down to two roles that matter operationally:
Owner: The single person who can make the call when things get stuck. Not a committee, not a role, not "the team." One human with a name and a Slack handle.
Blocker: Anyone whose work directly depends on the Owner delivering something specific by a specific date.
Here's what this looks like in practice. Marketing needs product screenshots for a launch campaign. Instead of building a full RACI showing product marketing is Responsible, VP of Marketing is Accountable, design is Consulted, and sales is Informed, you just have:
-
Owner
Jamie (Product Designer) — delivers screenshots by March 15
-
Blockers
Marketing team (campaign launch March 20)
When March 13 arrives and screenshots aren't ready, the system triggers. No meetings to figure out who to talk to. No confusion about decision rights. Jamie either delivers, delegates to someone else — making them the new Owner — or escalates to unblock herself.
Simple. And it actually gets used because it doesn't require a certification course to understand.
Building dependency boards that surface problems, not just track them
Most dependency tracking is archaeology — it documents what happened but doesn't prevent failures. By the time something shows up as "blocked" on your board, you're already behind.
A consumer fintech team had a beautifully maintained Jira board showing all their cross-team dependencies. Color-coded, linked tickets, the works. The problem was that "blocked" status only got updated after someone complained in a meeting. The board looked healthy right up until three projects slipped in the same week.
Effective dependency boards make three things visible at a glance:
Time until impact: How many days until this dependency blocks someone else's work? Dependencies with two-plus weeks get minimal attention. Dependencies with less than a week get daily check-ins. Anything under three days triggers automatic escalation.
Confidence level: Not a percentage or RAG status. A simple three-state indicator:
-
Clear path (owner knows exactly what to do and has everything needed)
-
Questions exist (owner needs clarification or resources)
-
Blocked (owner cannot proceed without external help)
Escalation readiness: Has the owner prepared an escalation package if needed? That means a specific ask, options with tradeoffs, and a recommended path forward.
The board structure follows a simple pattern:
| Dependency | Owner | Blocking | Days to Impact | Status | Escalation Ready |
|---|---|---|---|---|---|
| API endpoints | Dev Team B | Mobile release | 4 | Questions exist | No |
| Compliance review | Legal | Product launch | 11 | Clear path | N/A |
| Data migration | Infrastructure | Analytics rollout | 2 | Blocked | Yes |
Keep the 'Days to Impact' field front-and-center so teams notice approaching deadlines before they become crises.
Teams review this board on a fixed schedule, not random check-ins. Every Tuesday and Thursday at 2pm, dependency owners with less than a week to impact join a 15-minute standup. Not to give status updates — the board already shows that. The goal is to either resolve open questions or pull the trigger on escalations before they become emergencies.
Escalation lanes that bypass organizational molasses
Traditional escalation means scheduling meetings with increasingly senior people until someone finally makes a decision. By the time you've climbed the ladder, two weeks have passed and three other dependencies have gone critical.
Escalation lanes work differently. They're pre-negotiated paths for specific types of decisions, with clear triggers and committed response times.
Technical Escalation Lane
Trigger: Technical blocker with no clear owner or competing technical approaches Path: Blocked owner → Tech lead on call → Architecture review board (if needed) Response time: A couple hours for initial response, same day for decision
Resource Escalation Lane
Trigger: Need people or budget to unblock a dependency Path: Blocked owner → Resource pool manager → Department head Response time: Same day for smaller asks, next day for larger ones
Priority Escalation Lane
Trigger: Competing priorities between teams Path: Both owners → Shared manager → Priority committee (weekly) Response time: Two business days max, faster if blocking revenue or compliance
Each lane has a specific template the blocked owner fills out. Here's a rough example:
Situation: Data pipeline for customer analytics blocked on infrastructure capacity
Impact if delayed: Marketing can't launch personalization campaign — meaningful revenue impact, exact figure uncertain but enough to matter
What I need: Additional compute capacity for about three weeks
-
Delay campaign two weeks
-
Get temporary capacity at modest cost
-
Reduce another team's allocation — requires a priority call
Recommendation: Option 2
The escalation doesn't ask "what should we do?" It presents options with tradeoffs and makes a recommendation. Senior leaders can approve, modify, or redirect — but they can't punt the decision back down. That last part matters more than it sounds.
The phased dependency-triage ritual that keeps the system running
Governance systems die from neglect, not bad design. The board goes stale. Escalation lanes clog with non-critical noise. Ownership gets fuzzy as people change roles. Polished frameworks can fall apart within six weeks of launch because nobody built in maintenance rituals.
A phased triage ritual prevents this:
Phase 1: Daily Automation (No humans needed)
-
Updates days-to-impact for all dependencies
-
Flags anything that crossed the one-week threshold
-
Sends notifications to owners with under three days remaining
-
Archives completed dependencies
Phase 2: Twice-weekly Owner Sync (15 minutes)
-
Confirm status is accurate
-
Identify any new blockers
-
Prepare escalations if needed
-
Hand off ownership if circumstances changed
Phase 3: Weekly Leadership Review (30 minutes)
-
Review all triggered escalations
-
Audit dependencies with repeated delays
-
Adjust resource allocation if patterns emerge
-
Clear systemic blockers
Phase 4: Monthly Governance Retrofit (1 hour)
-
Analyzes escalation patterns — what keeps getting stuck?
-
Updates escalation lanes based on actual response times
-
Removes completed dependencies
-
Adjusts automation rules
What makes this sustainable is the progressive intensity. Daily automation handles routine updates. The twice-weekly sync catches emerging problems. Weekly leadership review handles escalations. Monthly retrofit keeps the system from calcifying. The whole thing adds maybe 90 minutes of human time per week per team — far less than the hours currently burned chasing status in Slack.
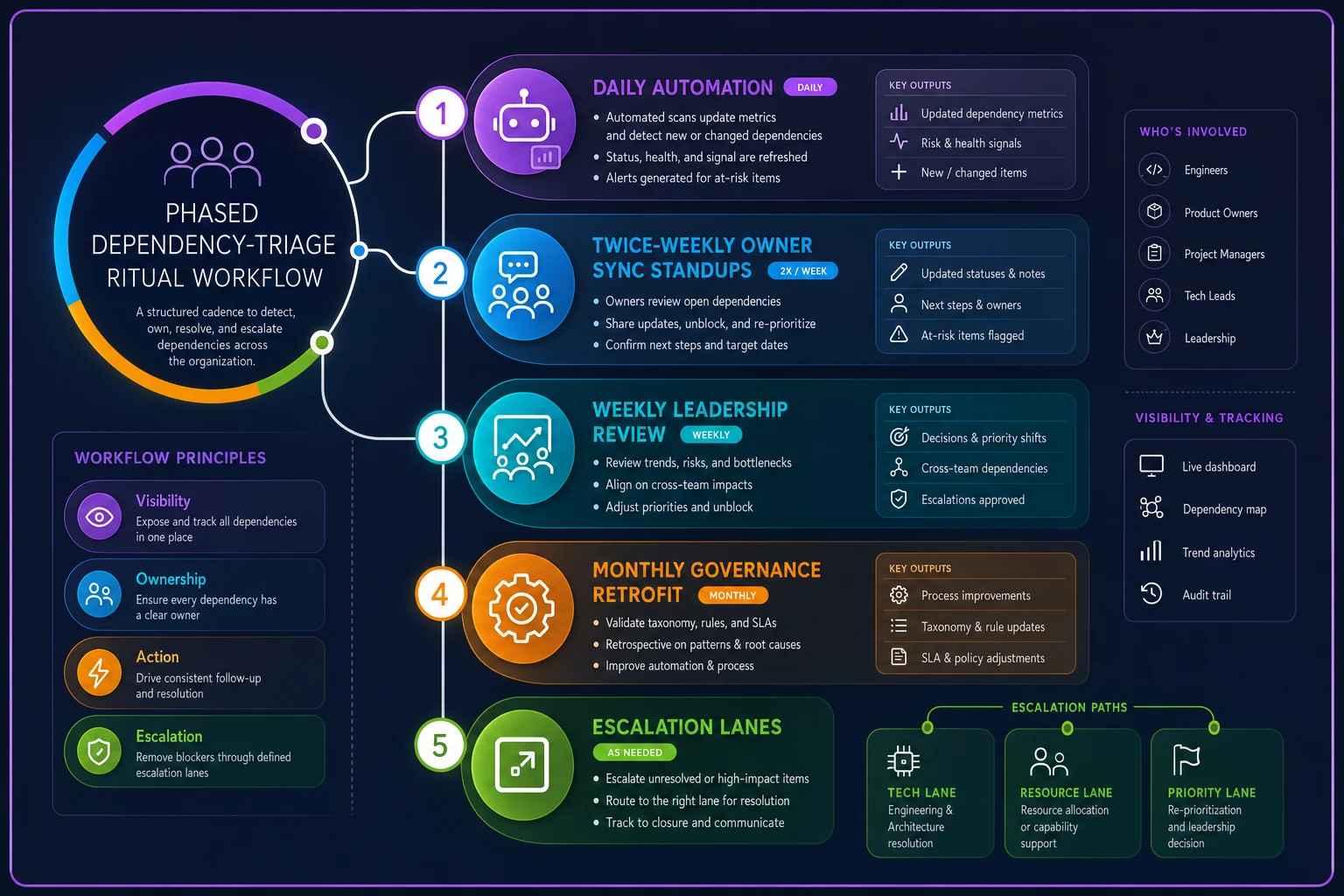
A simple diagram like this helps teams see when automation handles updates and when humans need to act.
Where traditional governance breaks and why teams accept the chaos
Most companies realize they need cross-team dependency governance after their third failed product launch. Not the kind where nothing ships — the kind where features ship broken because one team changed something another team depended on and nobody caught it in time. Or marketing launches a campaign for functionality that got quietly descoped two weeks earlier.
The reflexive response is always more process. More detailed RACI matrices. More status meetings. More approval gates. More documentation requirements. Operational reality works against heavy governance though. A typical product team touches a dozen or more other teams per quarter. Each has its own planning cycle, priority framework, and communication style. Maintaining perfect governance across all those touchpoints would consume more time than actually shipping anything.
So teams build shadow systems. Side channels on Slack. Dependencies negotiated through personal relationships. Buffer time hidden in estimates. The official process gets quietly abandoned because it doesn't reflect how work actually moves.
There's no shame in that — it's a rational response to a broken system. The framework described here acknowledges that reality. It doesn't try to document every dependency or control every decision. It creates just enough structure to prevent cascading failures while leaving room for teams to self-organize around what's actually happening day-to-day.
Implementation patterns that stick vs. those that get abandoned
Rolling out new governance usually follows a predictable failure pattern. Leadership announces the framework. Teams attend training. Everyone updates their spreadsheets for two weeks. Then quietly reverts to chaos.
One engineering director called it "governance theater" — everyone performs compliance long enough to say the rollout succeeded, then nothing actually changes.
Start with one critical dependency chain. Pick a single project with four or five teams involved. Implement RACI-lite just for this project. Run the dependency board just for these teams. Create escalation lanes just for their blockers.
Measure time-to-resolution, not compliance. Track how long dependencies stay blocked. Track how often escalations get used. Track whether blockers actually prevent other teams from progressing. Don't track whether people fill out forms correctly.
Make lightweight the default. When teams ask "do we need a full RACI?" the answer is no — use RACI-lite. When someone wants to track dependencies across ten fields, cut it to the six that matter. Complexity can always be added later if it's actually needed.
Automate before training. Set up the daily automation and notification systems before teaching anyone the process. Let the system remind people about approaching dependencies instead of relying on human discipline to keep things updated.
When lightweight governance becomes heavyweight (and what to do)
RACI-lite and dependency boards work reasonably well until you hit a critical mass of active dependencies or teams. Beyond a certain point — and it varies by organization — even lightweight governance starts creaking.
The symptoms show up gradually. Dependency boards become walls of red items. Everything feels critical. Escalation lanes trigger constantly. Owners spend more time in governance meetings than doing actual work.
One team described their dependency board as "a monument to our failures." They weren't wrong. Every item was urgent, nothing was moving, and the board had become a source of anxiety rather than clarity.
This is where AI-assisted operational platforms start making a real difference. Not by adding more process, but by handling the routine coordination that humans shouldn't be doing manually. Pattern recognition across dependencies surfaces hidden bottlenecks — that one backend team quietly blocking six or seven different projects. Automated impact analysis separates the delays that actually matter from the ones with hidden slack. Predictive alerts flag dependencies likely to slip based on historical patterns, not just approaching deadlines.
The governance framework stays the same. Updating statuses, calculating impact dates, preparing escalation packages — that gets automated. Teams keep ownership and decision-making. The software handles the bookkeeping and pattern-finding.
Adapting the framework for different organizational realities
The blueprint here assumes a typical product organization with relatively clear team boundaries. Dependency governance looks different across contexts.
Platform teams serving multiple product teams need reverse dependency tracking — not "what do I depend on" but "who depends on me." Their boards track upcoming breaking changes and deprecations, with automated notifications to dependent teams.
Distributed organizations can't run synchronous standups. They shift to async dependency reviews where owners update status by end-of-day their time, with escalations triggered if updates don't arrive within a day.
Regulated industries need additional approval gates but can fold them into escalation lanes. Compliance review becomes a standard lane with defined triggers and response times, not an ad-hoc process that randomly appears mid-project.
Small teams — under 30 people — might not need formal governance at all. But they still benefit from the RACI-lite discipline of naming single owners and understanding who gets blocked when work slips.
The compound effect of systematic dependency governance
Six months in, the operational improvements start compounding in ways that aren't obvious upfront.
Teams stop padding estimates because they trust dependencies to actually get delivered. Product launches stop failing from surprise blockers because problems surface weeks earlier instead of days. Engineers spend less time in coordination meetings because ownership is clear and escalation paths are defined.
The bigger shift is cultural. Teams stop treating dependencies as someone else's problem and start seeing them as shared operational challenges. The question changes from "why didn't your team deliver?" to "what prevented us from detecting this blocker earlier?" That's a completely different conversation.
The organization also builds muscle memory for handling cross-team complexity over time. New projects automatically identify owners and blockers. Teams instinctively prepare escalation packages when issues emerge. The dependency board becomes something people actually trust and update — which sounds basic, but is surprisingly rare in practice.
Making governance sustainable without constant oversight
The mistake most organizations make is treating governance like a project with an end date. They implement RACI matrices, declare victory, then wonder why everything falls apart three months later.
Sustainable governance needs three things working together. First, minimal viable process — just enough structure to prevent failures, not enough to slow down work. RACI-lite instead of full RACI. Six dependency fields instead of twenty. Three escalation lanes instead of complex approval matrices. Second, automation of repetitive tasks — humans shouldn't manually update days-to-impact or chase down status updates. AI-powered operational software handles the bookkeeping while humans handle decisions and exceptions. Third, regular but lightweight maintenance — the monthly retrofit takes one hour but prevents months of accumulated decay. The twice-weekly sync takes 15 minutes but catches problems while they're still solvable.
Start with your next cross-functional project, pick one critical dependency chain, and implement just enough governance to prevent that specific failure mode. Then expand gradually as teams see the value of systematic coordination over ad-hoc firefighting.
Cross-team dependency governance isn't about creating perfect documentation or eliminating uncertainty. It's about building operational systems that surface problems early, clarify ownership when confusion exists, and provide clear paths forward when teams get stuck. Start with your next cross-functional project, pick one critical dependency chain, and implement just enough governance to prevent that specific failure mode. Then expand gradually as teams see the value of systematic coordination over ad-hoc firefighting.
Ready to boost your team's productivity?
Join 5,000+ teams using Workyly to streamline workflows, improve communication, and deliver projects faster.

