

Delivery windows create operational chaos. You know the pattern: two weeks out, everything looks manageable. Then blockers surface, dependencies collapse, and suddenly three teams are scrambling to patch together a release that should've been flagged for delay five days ago.
The problem isn't tracking risks—most teams have spreadsheets full of them. The real issue is that risk management becomes this sprawling process where critical threats get buried under minor concerns, nobody owns specific mitigations, and follow-up happens whenever someone remembers to check.
A delivery risk triage system changes this. Not another risk register or complex framework—just a single-page operational tool that forces clarity around what actually threatens your delivery date.
Why traditional risk tracking fails near delivery windows
Risk management tends to break down exactly when you need it most—those final weeks before delivery. Teams document everything in detailed registers, run weekly reviews, assign RAG statuses, but somehow critical blockers still blindside them at the worst possible moment.
The core failure is that traditional risk tracking treats all risks equally. A potential vendor delay sits next to a minor UI inconsistency in the same list. Both get discussed, both get updates, both consume meeting time. But one could tank your entire release while the other just needs a quick post-launch fix.
Near-term delivery windows demand different operational logic. You're not managing theoretical future problems anymore—you're dealing with immediate threats that need owners, actions, and rapid verification. Standard risk processes can't handle this intensity.
What actually works is concentrating everything onto a single page that everyone references multiple times per week. No hunting through project folders, no confusion about who owns what, no ambiguity about which risks matter right now.
Building your one-page triage sheet
The entire system lives on one page—physical or digital, doesn't matter. What matters is the constraint. One page forces brutal prioritization and prevents the documentation sprawl that kills visibility.
Stop losing track of your priorities.
Workyly helps you organize, assign, and track every task efficiently.
- Centralized task management
- Real-time collaboration
- Intelligent workflow automation
No credit card required
Start with a simple grid. Left column lists risks. Next column shows your scoring. Third column names the mitigation owner—one person, not a team. Fourth column describes the specific mitigation action. Final column tracks your 48-hour check status.
Here's what makes this different from typical risk logs: you limit yourself to seven risks maximum. Not because there aren't more, but because human attention can't effectively track more than seven critical items simultaneously, especially under delivery pressure.
The scoring system stays binary and action-focused:
-
Critical (C)
Will definitely delay or break delivery if not resolved
-
High (H)
Likely to cause major rework or quality issues
-
Watch (W)
Could escalate but currently manageable
That's it. No medium, low, or informational categories. If something doesn't fit these three buckets, it doesn't belong on your delivery risk triage sheet.
The 48–72 hour ritual that maintains momentum
Static risk documents go stale within days. The real value comes from a rigid follow-up rhythm that fits naturally into delivery sprints.
Every risk gets checked at the 48-hour mark. Not reviewed, not discussed—actually checked. The mitigation owner confirms whether their action is working or if the risk needs escalation. This isn't a meeting. It's a quick async update that takes minutes.
At 72 hours, any unresolved critical risks trigger an automatic escalation. No judgment calls, no "let's give it another day"—if a critical risk hasn't moved after three days, it gets executive attention.
In practice, the ritual looks like this:
-
Monday 10am
New risks identified during morning standup get triaged onto the sheet
-
Wednesday 10am
All Monday risks get their 48-hour check
-
Thursday 4pm
Any remaining criticals from Monday escalate
-
Friday 2pm
Full sheet review and weekend handoffs if needed
This cadence creates predictable checkpoints without adding meetings. Teams know exactly when risks will be reviewed and when escalations happen. The predictability itself reduces anxiety around delivery dates.
Here's a simple workflow showing the 48–72 hour check and escalation flow.
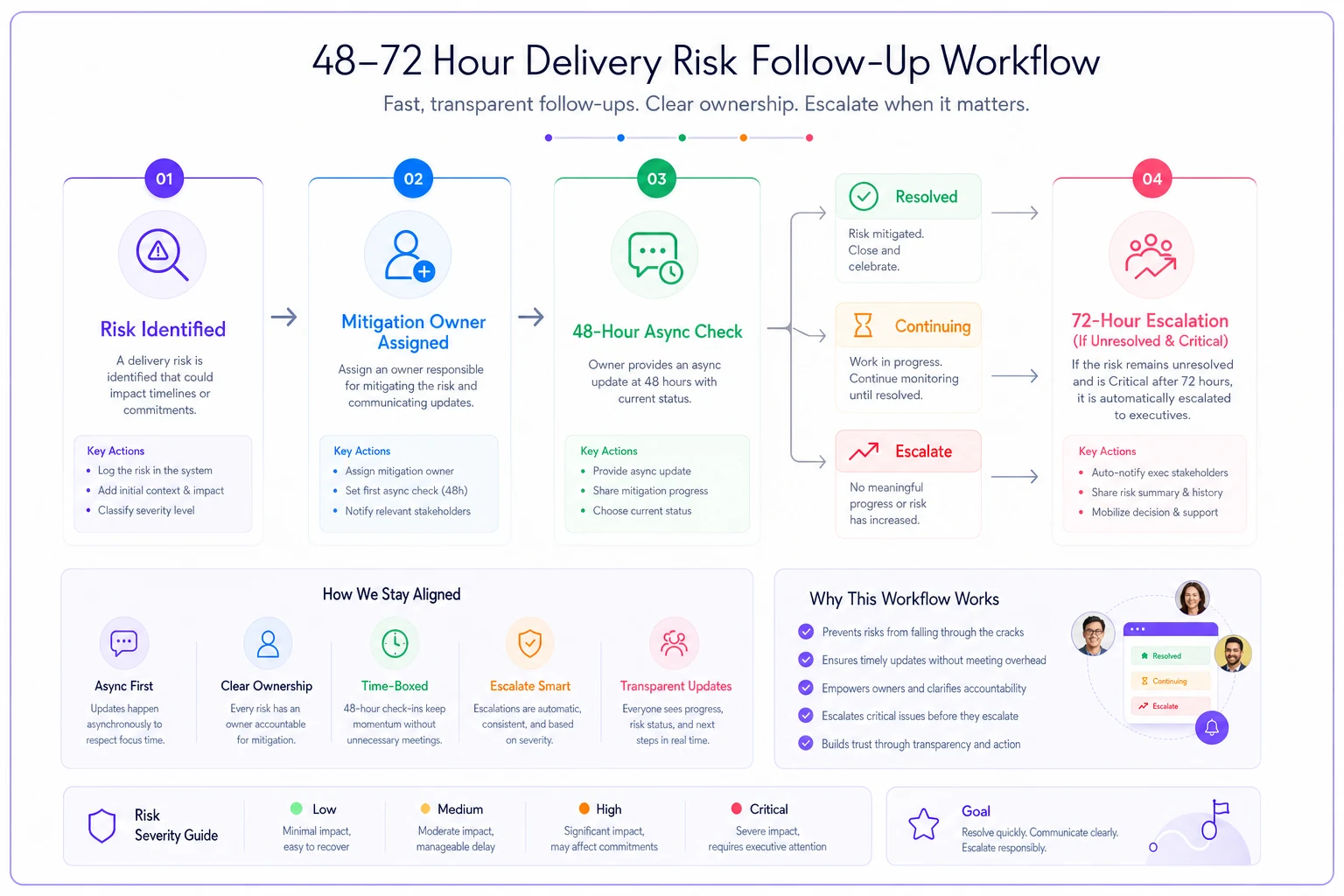
In practice, the ritual keeps momentum and forces timely decisions rather than open-ended discussions.
Who owns what: eliminating mitigation confusion
Shared ownership means no ownership. Every risk on your triage sheet needs one person's name next to it—not "DevOps team" or "QA will handle," but an actual human who feels personal responsibility for that mitigation.
This feels uncomfortable at first. People prefer spreading responsibility across teams. But diffuse ownership is exactly why critical risks slip through. When everyone owns a piece, nobody owns the outcome.
The mitigation owner doesn't need to personally fix everything. They coordinate, escalate, and verify. They're the single point of contact when you need an update, and they know whether the mitigation is working or failing.
Assignment happens during triage based on three factors:
-
Who has the most context about the risk?
-
Who has the relationships needed to fix it?
-
Who has the least critical work over the next 48 hours?
Pick an owner who can act in the next 48 hours, not necessarily the subject matter expert.
That last factor matters. You're not always assigning the subject matter expert. Sometimes the best owner is whoever has capacity to actually drive the mitigation forward right now.
Scoring methodology that actually predicts delays
Most risk scoring systems fail because they try to calculate precise probabilities and impact scores. Near delivery, you don't need precision—you need clarity about what could actually stop shipment.
Scoring happens through three quick questions:
Question 1: If this risk materializes today, do we miss our delivery date? If yes → Critical
Question 2: If this risk materializes, do we need significant rework (more than 16 hours)? If yes → High
Question 3: Could this risk escalate to High or Critical within 72 hours? If yes → Watch If no → Remove from triage sheet
This binary approach eliminates scoring debates. Either something threatens delivery or it doesn't. Either it needs rework or it doesn't.
When teams first implement this, they resist removing lower risks from the sheet. There's comfort in tracking everything. But comprehensive tracking is exactly what obscures critical threats. Your delivery risk triage focuses only on what could actually derail you in the next few days.
Real scenario: SaaS platform launch
A B2B SaaS company preparing for a major platform update demonstrates how this system prevents last-minute scrambles. Their previous launches consistently slipped by 5–10 days, burning around $15,000 in contractor extensions each time.
Three weeks before launch, they implemented the one-page triage system. Their initial sheet looked like this:
| Risk | Score | Owner | Mitigation | 48hr Status |
|---|---|---|---|---|
| Payment gateway integration failing tests | C | Marcus | Direct escalation to gateway vendor | Pending |
| Customer data migration script errors | C | Sarah | Parallel manual migration prep | Pending |
| iOS app store review delays | H | David | Pre-submission review scheduled | Pending |
| Documentation incomplete | W | Lisa | Contractor brought in for two days | Pending |
| Performance degradation on large accounts | H | Marcus | Caching layer implementation | Pending |
Notice how specific these are. Not "integration issues" but "payment gateway integration failing tests." Not "performance problems" but "performance degradation on large accounts." Specificity enables targeted mitigation.
After 48 hours, two critical risks had resolved, but the iOS review risk escalated to Critical when Apple announced a holiday review slowdown. David immediately initiated their backup plan—launching web-first with iOS following.
The launch hit its date with only minor documentation delays. First time in two years they hadn't needed deadline extensions.
When scoring conflicts arise
Teams argue about scores. Someone thinks a risk is Critical, another sees it as High. These debates can consume entire meetings if you let them.
The tiebreaker rule: whoever would own the mitigation makes the final scoring call. They're closest to the problem and will be accountable for the fix. This prevents extended discussions and forces ownership mindset from the start.
If the proposed owner genuinely can't decide between Critical and High, default to Critical. Over-caution near delivery beats surprise delays. You can always downgrade after the 48-hour check if mitigation is working.
Some teams modify this slightly—the delivery manager gets override authority on any score, but must then become the mitigation owner if they upgrade something to Critical. Stops arbitrary upgrades while maintaining ultimate accountability.
Common pitfalls in the first week
The first week running delivery risk triage tends to surface the same three mistakes.
First, teams try to track too many risks. The seven-risk limit feels arbitrary until you realize attention is finite. Every risk beyond seven dilutes focus on the truly critical items. If you genuinely have twelve critical risks, you're not ready for delivery.
Second, they assign mitigation to teams instead of individuals. "Platform team will investigate" becomes "Jennifer will investigate by Wednesday 2pm." The specificity changes everything. Jennifer knows she's accountable. The platform team assumes someone else will handle it.
Third, they skip the 48-hour checks when things seem stable. This is exactly when hidden problems metastasize. That vendor who promised a fix by Tuesday doesn't deliver. The workaround that seemed solid starts showing edge cases. Skipping checks means surprises later.
The system works because of its constraints, not despite them. One page, seven risks, binary scoring, individual owners, rigid check intervals. Remove any element and effectiveness drops immediately.
Integrating with existing project rhythms
Delivery risk triage doesn't replace existing project management—it supplements it during critical windows. Think of it as switching from normal operations to battle stations when delivery approaches.
When to activate triage varies by team size and project complexity. Small teams might turn it on two weeks before delivery. Larger programs might need four weeks. The key signal: when daily standups start focusing more on blockers than progress.
During active triage, the one-page sheet becomes your primary risk artifact. Other risk registers and project trackers continue but take secondary priority. Everyone knows the triage sheet represents ground truth for delivery readiness.
Some teams display the triage sheet on a physical wall or permanent monitor. Others pin it in Slack or Teams. Location matters less than universal visibility. When someone asks "what could delay us?", everyone should immediately reference the same document.
The sheet also drives different conversations. Instead of broad risk reviews, discussions become specific: "Marcus, what's the latest on the payment gateway?" "Sarah, do we need to trigger manual migration?" These targeted queries replace meandering risk meetings.
For teams working through larger delivery backlogs or managing intake pressure alongside execution, this pairs well with a structured intake and SLA triage approach—keeping both incoming work and active delivery risks visible without one swamping the other.
Preventing triage theater
Some teams go through the motions without getting value. They create the sheet, assign owners, run checks, but still hit surprise delays. Usually, this happens because they're performing triage theater instead of actual risk management.
Theater looks like: risks stay vague ("integration issues"), owners don't have real authority, mitigation actions are passive ("monitor situation"), and 48-hour checks become status updates instead of verification.
Real triage requires uncomfortable specificity. Risks name exact systems and failure modes. Owners can make decisions without multiple approvals. Mitigations describe concrete actions with measurable outcomes. Checks verify whether mitigations actually reduced risk.
The difference shows in the language. Theater says "we're watching the vendor situation." Real triage says "Marcus called the vendor escalation line at 2pm, they've committed to a fix by Thursday noon, and if they miss it we implement the manual workaround."
This level of operational detail feels excessive until you realize it's the only thing that prevents last-minute surprises. Vague risks hide real problems. Specific risks get solved.
Making it sustainable with operational software
Manual triage sheets work but require discipline. Someone needs to update statuses, track check intervals, and chase down owners. This administrative overhead often causes teams to abandon the system after a few cycles.
AI-powered operational software can reduce that friction significantly. Instead of manually tracking 48-hour intervals, the platform automatically prompts owners for updates. Instead of chasing people for status, notifications go out automatically. Instead of updating sheets, owners click a simple "resolved/escalated/continuing" status.
The more useful acceleration comes from pattern recognition over time. After several delivery cycles, AI automation can surface which types of risks typically escalate, which mitigations tend to work, and which owners consistently resolve issues quickly. That institutional knowledge gets embedded into the triage process instead of living in someone's head.
Modern platforms can also connect triage directly to actual delivery systems. When a risk involves deployment pipelines, the software monitors those pipelines directly. When customer data migration is flagged, it tracks migration job status in real-time. The triage sheet becomes a living document fed by operational data rather than manual updates.
But the core discipline remains human. Software reduces administrative burden and improves visibility—it doesn't decide what's truly Critical, who should own a mitigation, or when escalation is warranted. Those are still judgment calls.
The compound effect of consistent triage
Teams that run delivery risk triage across multiple cycles see improvements that compound. Not just in on-time delivery, but in overall operational maturity.
After three or four deliveries, patterns emerge. Certain types of risks appear repeatedly. Specific vendors consistently cause delays. Some team members handle particular mitigations better than others. This knowledge accumulates into something useful—real institutional wisdom about managing delivery windows.
The triage discipline also shifts team culture. People start identifying risks earlier because they know those risks will end up on someone's triage sheet. Mitigation planning becomes more proactive. The 48-hour rhythm creates accountability that extends beyond risk management.
And delivery anxiety genuinely decreases. Teams know that critical threats won't hide until the last minute. There's a system for surfacing, owning, and verifying risks. That confidence allows teams to push ambitious delivery dates without the usual late-stage panic.
For teams also dealing with WIP pressure during delivery crunches, it's worth reading through team-specific WIP limit configurations—the same principle of forcing constraints to create focus applies there too.
Beyond delivery windows
While designed for near-term delivery pressure, the triage principles apply to other operational crunches. Product launches, customer implementations, infrastructure migrations—any time-boxed critical operation benefits from this focused approach.
The key is maintaining the constraints. One page, limited risks, individual owners, rapid check cycles. These elements create the operational pressure that forces clarity and action. Remove the constraints and you're back to traditional risk management with all its diffusion and delay.
Some teams run quarterly "triage weeks" even without specific deliveries—identifying the seven most critical operational risks facing the business and applying the same focused resolution process. It prevents the accumulation of technical debt and operational friction that eventually creates crisis.
The system's simplicity is its strength. No special tools, no complex processes, no extensive training. Just a commitment to surface critical risks, assign clear owners, and verify progress every 48 hours. Any team can start tomorrow with nothing more than a shared document and the discipline to maintain the rhythm.
Delivery pressure reveals operational reality. The teams that thrive have systems for managing that pressure instead of just enduring it. The delivery risk triage becomes that system—turning chaos into a predictable process that consistently hits dates without burning people out in the process.
The constraints feel limiting at first. Seven risks feels too few. Individual ownership feels too concentrated. 48-hour checks feel too frequent. But these are exactly what create the focus that prevents delays. In the intensity of near-term delivery windows, constraints are your operational advantage.
Ready to boost your team's productivity?
Join 5,000+ teams using Workyly to streamline workflows, improve communication, and deliver projects faster.

