

Rep. Nathaniel Moran introduced legislation yesterday that would fundamentally change how product teams handle AI failures. The bill requires companies to report AI incidents to the Commerce Department within specific timeframes—sometimes as short as 72 hours for critical issues.
For teams shipping AI features, this isn't just another compliance checkbox. According to Reuters, the proposed legislation covers everything from dangerous capabilities to security breaches, with penalties that could seriously damage both your product roadmap and your budget.
What the news coverage keeps missing: most product teams have zero operational infrastructure to detect these incidents in the first place, let alone report them within regulatory windows.
The hidden operational nightmare nobody's talking about
Picture the actual scenario. Your team ships a customer service chatbot. Three weeks later, it starts hallucinating refund amounts—telling customers they're owed $500 when the real number is $50. Under this proposed law, that's potentially a reportable incident. But most teams wouldn't know it was happening until angry customers start posting about it publicly.
The operational gap is massive. Product teams typically track feature adoption, engagement metrics, maybe some error rates. AI incident reporting requires something completely different—you need to know when your model does something unexpected, harmful, or outside its intended scope. That's not a metric sitting in your dashboard. It's not in your logging. It probably doesn't even have a clear definition in your documentation.
-
Real-time monitoring for behavioral anomalies
-
Classification rules for what actually constitutes an "incident"
-
Audit trails that can reconstruct exactly what happened
-
Clear escalation paths with defined owners
-
Documentation that holds up under regulatory scrutiny
Most teams barely have solid monitoring for their regular features, let alone this level of operational depth for AI components.
Why traditional incident management completely fails for AI
Traditional incident management assumes predictable failure modes. Server goes down. Database locks up. API times out. These are binary states—working or broken.
Stop losing track of your priorities.
Workyly helps you organize, assign, and track every task efficiently.
- Centralized task management
- Real-time collaboration
- Intelligent workflow automation
No credit card required
AI incidents don't work that way. Your model doesn't "break" in the traditional sense. It drifts. It hallucinates. It develops biases. It makes decisions that are technically within its parameters but ethically questionable or legally problematic.
A financial services team I worked with discovered their loan approval model had developed a geographic bias—approving roughly 40% fewer applications from certain zip codes. The model was functioning perfectly from a technical standpoint. Response times normal, accuracy metrics fine. But it was creating massive legal exposure that standard monitoring completely missed.
Detection gets harder when you realize AI incidents often emerge from edge cases. Your sentiment analysis works great on standard customer feedback but starts categorizing legitimate complaints as positive when customers use sarcasm. Your recommendation engine performs well overall but consistently surfaces inappropriate content for users under 18. These aren't system failures—they're capability failures that only appear in specific contexts.
Building detection systems that actually catch AI incidents
Forget what you know about error monitoring. AI incident detection requires a different operational approach entirely.
Start with behavioral baselines, not error thresholds. Track your model's decision distribution over time. If your content moderation AI typically flags 8–12% of posts, a sudden drop to 2% or spike to 25% signals something's wrong—even if the system is technically "working."
The framework that actually holds up in practice:
Layer 1: Output distribution monitoring Track the statistical distribution of your model's outputs. Set up alerts when distributions shift beyond normal variance. This catches drift before it becomes an incident.
Layer 2: Decision reversals and corrections Monitor how often human reviewers overturn AI decisions. A spike in reversals means your model is making problematic judgments that standard metrics miss.
Layer 3: Contextual anomaly detection Build checks for specific high-risk scenarios. If your pricing algorithm suggests prices 50% above historical ranges, flag it. If your chatbot starts giving medical advice when it's supposed to handle product support, catch it immediately.
Layer 4: User behavior signals Track what users do right after interacting with your AI. Rapid task abandonment, immediate escalations to human support, or unusual complaint patterns all signal potential incidents your technical monitoring didn't catch.
AI Incident Detection Flow [AI Output Generated] ↓ [Distribution Monitor] → Flags anomaly? ↓ No ↓ Yes [Decision Reversal Check] [Alert Triggered] ↓ ↓ [Contextual Checks] [Classification begins] ↓ ↓ [User Signal Monitor] [Escalation workflow] ↓ [No incident logged]
Here's a simple operational flow that captures the detection process.
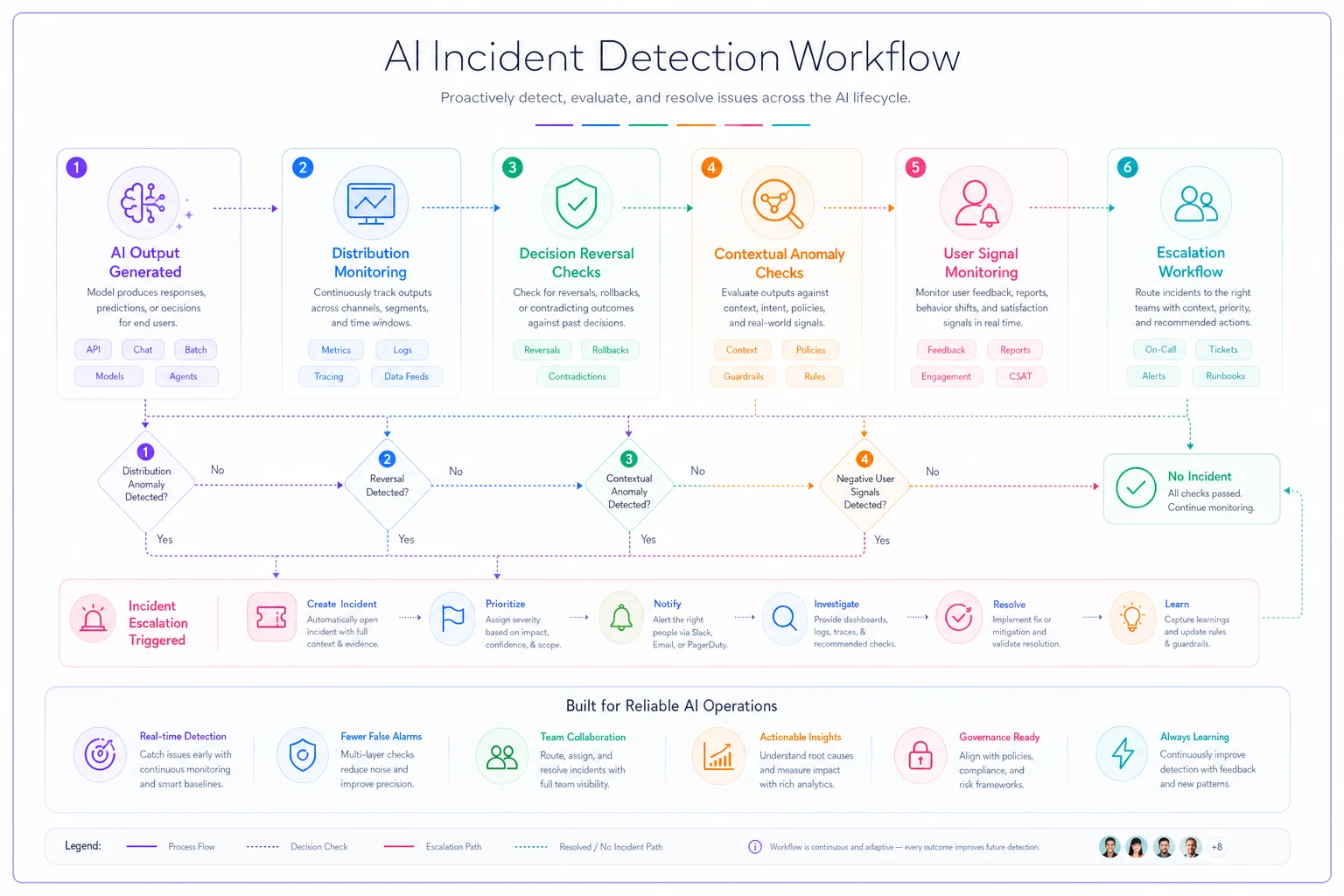
Start by tracking only a few high-risk distributions to get immediate value before expanding coverage.
This layered approach gives you multiple signals so a single missed metric doesn't mean a missed incident.
The classification challenge that will sink your compliance
Even perfect detection means nothing if you can't classify incidents correctly. The proposed legislation mentions "dangerous capabilities" and "critical incidents"—but what exactly qualifies?
Most teams default to severity levels like P1, P2, P3. That framework falls apart with AI incidents. A chatbot giving incorrect product information might look like a P3 issue until you realize it's systematically misleading customers about warranty terms, creating significant legal exposure.
| Impact Domain | Example Incidents | Reporting Risk |
|---|---|---|
| Legal / Regulatory | Discriminatory outputs, privacy violations, misleading financial info, health misinformation | High |
| Operational | Systematic errors in core workflows, automation failures, integration breakdowns | Medium–High |
| Reputational | Outputs likely to go viral negatively, consistent poor UX, trust-breaking behavior | Medium |
Each domain needs specific thresholds and real examples. A dating app's matching algorithm showing bias requires different classification than a medical diagnosis AI making errors. Your classification system has to account for your specific context while staying flexible enough to handle incident types you didn't anticipate.
Creating audit trails that survive regulatory scrutiny
When regulators come—and they will—you need more than logs. You need a complete operational record explaining not just what happened, but why your team made specific decisions.
Standard logging captures events. Regulatory-grade audit trails capture context, decisions, and accountability.
-
The complete input that triggered the problematic output—not just the user query, but the full context window, any retrieved documents, active feature flags, and model version.
-
The actual output and why your system classified it as problematic. Include confidence scores, alternative outputs considered, and any post-processing applied.
-
The detection timeline—when the incident occurred versus when you discovered it. Regulators care about detection lag more than most teams realize.
-
Your team's response actions with timestamps and named owners. Who was notified? What decisions were made? What mitigation steps were taken?
-
Proof that the incident was actually resolved—test results, validation checks, and sign-offs from relevant stakeholders.
Building this kind of audit infrastructure takes time. Teams that start now will have something defensible. Teams that wait until after legislation passes will be scrambling.
Escalation workflows that match regulatory timelines
Seventy-two hours sounds like plenty of time until you factor in detection lag, classification debates, and legal review. Your escalation workflow needs to operate on a completely different timeline than typical incident response.
Traditional escalation might give engineers 24 hours to investigate before looping in leadership. With AI incident reporting requirements, you need parallel tracks from minute one.
The engineering track handles technical investigation and immediate mitigation. They're figuring out what went wrong and how to stop it.
The compliance track starts documenting everything for potential reporting. They're building the narrative regulators will want to see.
The legal track evaluates exposure and reporting obligations—determining if this actually requires reporting and what the implications are.
The product track assesses feature impact and manages customer communication while the technical side handles the fix.
These tracks must run simultaneously, not sequentially. By the time engineering fully understands the problem, compliance should already have a draft report ready.
Setting up ownership without creating bureaucratic nightmares
Clear ownership sounds simple until you realize AI incidents cross every organizational boundary. A recommendation algorithm issue touches engineering, product, legal, compliance, and possibly marketing. Who actually owns it?
The model owner structure fails because the same model often powers multiple features across different teams. The feature owner structure fails because AI incidents regularly span features. The domain owner structure fails because incidents rarely fit neatly into predefined categories.
What works is a rotating incident commander model with domain deputies. Assign a primary incident commander who coordinates the overall response regardless of technical domain. Then designate deputies from each affected area who own their specific workstream.
Your customer service chatbot starts giving medical advice. The incident commander—pulled from your on-call rotation—coordinates the response. The AI/ML deputy handles model investigation. The legal deputy evaluates liability. The product deputy manages feature flags and customer communication. The compliance deputy prepares regulatory filings.
This maintains clear accountability while keeping domain expertise involved. The incident commander doesn't need to understand transformer architectures. They need to make sure the ML deputy who does is unblocked and delivering updates.
Measuring mitigation effectiveness (not just speed)
Everyone measures time-to-resolution. Almost nobody measures whether the mitigation actually worked. With AI incidents, a fast fix that doesn't address the root cause just creates future regulatory exposure.
Track mitigation effectiveness across three dimensions:
Immediate effectiveness: Did the mitigation stop the problematic behavior? Measure this through synthetic tests, not just the absence of new reports.
Durability: Does the fix hold up over time and across contexts? Run regression tests with edge cases to make sure you didn't patch one scenario while leaving others exposed.
Completeness: Did you address the root cause or just the symptom? If your chatbot was hallucinating prices, did you fix the specific hallucination or the underlying tendency to generate unverified information?
Most teams consider an incident resolved when alerts stop firing. Regulators will want proof that your mitigation prevents similar incidents—which requires a completely different measurement approach than what most teams currently have in place.
The resource reality nobody wants to discuss
This level of operational sophistication requires serious resources. Not just engineering time—specialized expertise most teams don't currently have.
A mid-sized product team shipping AI features probably needs:
-
2–3 engineers focused on monitoring and detection systems
-
1 dedicated compliance role with real understanding of regulatory requirements
-
Legal counsel actually familiar with AI regulations
-
Operational tooling beyond standard APM solutions
-
Allocated time for incident preparation and regular drills
That's probably somewhere in the $400k–$600k range in additional annual cost, at minimum. For enterprises shipping AI features across multiple teams, multiply accordingly.
The alternative is accepting significant regulatory risk or dramatically scaling back AI ambitions. Neither is a great option, and pretending the cost doesn't exist doesn't make it go away.
Turning this into competitive advantage
Solid AI incident management isn't just about compliance—it's about shipping better features faster.
Teams with mature incident processes catch problems in staging, not production. They identify model drift before customers complain. They understand their AI's failure modes and design around them from the start.
One fintech company built comprehensive incident detection for compliance reasons but discovered it caught quality issues weeks earlier than their previous approach. Their model retraining cycles dropped from quarterly to monthly because they had better signals about when retraining was actually needed. That wasn't the plan—it was just what happened when you build operational visibility into your AI infrastructure.
The audit trails you build for regulators become debugging tools for engineers. The classification system for incidents becomes the prioritization framework for improvements. There's real compounding value here that goes well beyond avoiding fines.
Your next 30 days
Week 1–2: Audit current state Map every AI feature in production. Document current monitoring. Identify detection gaps. Figure out who would own an incident if one happened today.
Week 2–3: Build basic detection Implement output distribution tracking. Set up decision reversal monitoring. Create simple anomaly alerts. Don't aim for perfection—aim for visibility.
Week 3–4: Establish workflows Define your incident commander rotation. Create escalation templates. Draft classification criteria. Run a tabletop exercise with a hypothetical incident.
Week 4+: Iterate and expand Refine detection based on false positives. Expand monitoring coverage. Build automation where manual processes create bottlenecks. Document lessons from real incidents as they happen.
The teams that come out ahead under AI regulation won't have perfect compliance programs. They'll be the ones who turned compliance requirements into operational discipline—building the kind of systematic risk detection and rapid response systems that make their AI features more reliable, more trustworthy, and ultimately more valuable to customers.
Don't wait for the regulation to force your hand. The operational capabilities you need for compliance are the same ones you need for quality. Start building them now, while you still have time to do it right.
The uncomfortable truth about AI operations
Most product teams treat AI features like regular code—ship it, monitor errors, fix bugs. But AI operates differently. It makes decisions you didn't explicitly program. It learns patterns you didn't anticipate. It fails in ways that are genuinely hard to predict.
The proposed incident reporting legislation just makes visible something that should've been obvious earlier: shipping AI without operational depth is like performing surgery without imaging equipment. You might get lucky for a while, but when something goes wrong, you're flying blind.
Teams that recognize this and build accordingly won't just avoid regulatory penalties. They'll ship AI features that actually work—consistently, predictably, and in ways customers can actually trust. In a market full of half-baked AI implementations, that's a real advantage worth building toward.
Teams that recognize this and build accordingly won't just avoid regulatory penalties. They'll ship AI features that actually work—consistently, predictably, and in ways customers can actually trust. In a market full of half-baked AI implementations, that's a real advantage worth building toward.
Ready to boost your team's productivity?
Join 5,000+ teams using Workyly to streamline workflows, improve communication, and deliver projects faster.